Welcome to CS265 Big Data & AI Systems. This is a research-oriented class about the fundamental principles behind big data & AI systems for diverse data science applications. This year the focus will be specifically in NoSQL, LLMs, RAG, and Image AI. The paper/class schedule shown below is from last year - the new schedule will be available in mid-January. The Syllabus is available here. The paper schedule is tentative and there will likely be some small updates.
Big data is everywhere. A fundamental goal across numerous modern businesses and sciences is to be able to exploit as many machines as possible, to consume as much information as possible and as fast as possible. The big challenge is "how to turn data into useful knowledge". This is a moving target as both the underlying hardware and our ability to collect data evolve. In this class, we will discuss how to design systems and algorithms for key data-driven areas, including relational systems, distributed systems, graph systems, noSQL, newSQL, machine learning and neural networks. We will see how they all rely on the same set of very basic concepts and we will learn how to synthesize efficient solutions for any problem across these areas using those basic concepts.
In each class we will read one recent research paper and the instructor will lead a discussion around the technical aspects of the work but crucially also on how the fundamental concepts of this work connect with other fields, applications and problems. Students will write two reviews (summary, critique, ideas) per week on the assigned papers for discussion. Each student is expected to present at least once during the semester: each class starts with a short presentation by a student for the paper of the day. In addition, each student will participate in a semester long project (systems or research project). Research projects are integrated with the work at DASlab and are meant to lead to a research publication within the next 1-2 years.
Central Learning Outcomes: Understanding fundamental concepts in data storage and access; Learning to read and quickly understand research papers; Learning to prepare and deliver clear presentations on complex topics; Getting a feeling on what it means to do research.
CS265 has unlimited office hours, unlimited late days for project deliverables, relies on the latest research papers instead of a standard text book, lectures are based on interaction and discussion instead of just "lecturing", many of the quizzes and problem sets are actually open research problems and most of all it is fun! The instructor and the TFs are here to help you every day and at all times throughout the semester. You may request as many meetings as you like and as much help as you want.
The class is also geared towards engaging creative thinking and problem solving to give students a feeling of how computer science research takes place. Many of our students in the past have successfully engaged in research projects with DASlab and published research papers.
The class meets twice a week.
We will discuss the logistics and goals of the course and introduce the idea that all data-driven algorithms, models, and systems rely on a small set of fundamental design concepts. Understanding these concepts in detail allows one to optimize any data-driven process from individual algorithms to SQL, NoSQL, Big Data systems, Neural Networks, and many more.
Download SlidesWe will introduce the concept of self-designing systems: systems that can automatically adapt their design to different hardware, application workloads, and performance requirements. We will discuss how to discover the fundamental design principles in major storage schemes and show how understanding the design space can improve modern system designs by orders of magnitude.
Download SlidesWe will introduce Retrieval Augmented Generation (RAG), a paradigm that enhances large language models by grounding their responses in external knowledge retrieved at query time. We will cover the core RAG pipeline components including document chunking, embedding, indexing, retrieval, and generation, and discuss the key design decisions and tradeoffs that affect RAG system quality and performance.
Download SlidesWe will explore how the self-designing paradigm applies to RAG systems, enabling them to automatically adapt their configuration to different data collections, query workloads, and quality requirements. We will discuss how to navigate the large design space of RAG pipelines and how to automatically select the best combination of chunking strategies, embedding models, retrieval methods, and generation parameters.
Download SlidesWe will explore how the self-designing approach applies to image AI systems, where the storage format and data pipeline can be co-designed with the AI model to dramatically improve inference performance. We will discuss how self-designing storage formats can replace traditional image formats like JPEG, adapting to specific hardware and model requirements to achieve significant speedups.
Download SlidesContinuing from the previous class, we will dive deeper into the design space of image AI systems, covering advanced techniques for self-designing storage and data loading pipelines. We will discuss how to automatically adapt the end-to-end image processing pipeline to different hardware configurations, model architectures, and application workloads to maximize throughput.
Download SlidesWe will provide a broad overview of the self-designing paradigm for AI systems, showing how systems can automatically adapt their design to different hardware, application workloads, and performance requirements. We will discuss the key principles, including design space exploration, learned cost models, and automatic configuration, and how they apply across diverse AI system domains.
Download SlidesWe will provide a broad overview of the self-designing paradigm for AI systems, showing how systems can automatically adapt their design to different hardware, application workloads, and performance requirements. We will discuss the key principles, including design space exploration, learned cost models, and automatic configuration, and how they apply across diverse AI system domains.
Download SlidesWe will cover the fundamentals of GPU programming and performance engineering, including GPU architecture, memory hierarchy, parallelism models, and common optimization techniques. Understanding GPU internals is essential for designing high-performance AI systems, and we will discuss how to identify and address performance bottlenecks in GPU workloads.
Download SlidesWe will discuss how to apply the self-designing paradigm to build performant LLM systems that automatically adapt to different model sizes, hardware configurations, and serving requirements. We will cover key system design decisions in LLM inference and training, including memory management, batching strategies, and parallelism, and how these can be automatically optimized.
Download SlidesWe will introduce the systems challenges of LLM fine-tuning, covering how to efficiently adapt large pre-trained models to specific tasks and domains. We will discuss the design space of fine-tuning approaches from a systems perspective, including memory optimization, distributed training strategies, and how self-designing principles can automatically select the best configuration for a given model, dataset, and hardware setup.
Download SlidesContinuing from the previous class, we will dive deeper into the systems design space of LLM fine-tuning, covering advanced techniques for memory-efficient training, parameter-efficient methods, and how self-designing principles can automatically optimize the fine-tuning pipeline for different models and hardware configurations.
Download SlidesTri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, Christopher Ré. NeurIPS 2022
Download SlidesTianqi Chen, Thierry Moreau, Ziheng Jiang, Lianmin Zheng, Eddie Yan, Haichen Shen, Meghan Cowan, Leyuan Wang, Yuwei Hu, Luis Ceze, Carlos Guestrin, Arvind Krishnamurthy. OSDI 2018
Download SlidesNo Class: University Spring Recess
No Class: University Spring Recess
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, Yuxiong He. SC 2020
Download SlidesYanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Less Wright, Hamid Shojanazeri, Myle Ott, Sam Shleifer, Alban Desmaison, Can Balioglu, Pritam Damania, Bernard Nguyen, Geeta Chauhan, Yuchen Hao, Ajit Mathews, Shen Li. VLDB 2023
Download SlidesWoosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, Ion Stoica. SOSP 2023
Download SlidesYinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, Hao Zhang. OSDI 2024
Download SlidesRuoyu Qin, Zheming Li, Weiran He, Jialei Cui, Feng Ren, Mingxing Zhang, Yongwei Wu, Weimin Zheng, Xinran Xu. FAST 2025 (Best Paper)
Download SlidesMengdi Wu, Xinhao Cheng, Shengyu Liu, Chunan Shi, Jianan Ji, Man Kit Ao, Praveen Velliengiri, Xupeng Miao, Oded Padon, Zhihao Jia. OSDI 2025
Download SlidesLianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, Ying Sheng. NeurIPS 2024
Liana Patel, Siddharth Jha, Melissa Pan, Harshit Gupta, Parth Asawa, Carlos Guestrin, Matei Zaharia. VLDB 2025
Siddhant Ray, Rui Pan, Zhuohan Gu, Kuntai Du, Shaoting Feng, Ganesh Ananthanarayanan, Ravi Netravali, Junchen Jiang. SOSP 2025
Xin Tan, Yimin Jiang, Yitao Yang, Hong Xu. ASPLOS 2025
Ying Sheng, Shiyi Cao, Dacheng Li, Coleman Hooper, Nicholas Lee, Shuo Yang, Christopher Chou, Banghua Zhu, Lianmin Zheng, Kurt Keutzer, Joseph E. Gonzalez, Ion Stoica. MLSys 2024
Data systems are literally everywhere. We are using them directly or indirectly every day all day long for numerous basic or not so basic tasks, e.g., when we are buying coffee to when we are booking airplane tickets. They provide the backbone of all modern businesses to manage their data and of course they provide the backbone of online businesses and environments such as social networks and search engines. They are also used increasingly in science as data analytics becomes more and more the fundamental barrier in generating knowledge.
This class is not a traditional introduction on how we use a database system and how to write SQL. Instead, this is a systems class about data system design. You will learn how big data & AI systems work at their core and how to design new systems for emerging applications and hardware. By the way, if you know how systems work, you also become better at using them!
Data is everywhere. Every year we create even more data. As it stands, every two days we create as much data as much we created from the dawn of humanity up to 2003 [Eric Schmidt, Google]. Sciences, businesses, and everyday life are substantially affected. Data systems are in the middle of all this. Data systems are how we store and access data, i.e., they are the backbone of any data-driven application. It is a $100B industry, growing 10% every year [Economist, “Data, data everywhere”].
At the same time data systems research and the whole industry are going through a major and continuous transition; given that new data-driven scenarios and applications continuously pop up, there is a continuous need to redefine what is a good data system design in such a dynamic environment.
CS265 exposes students to the core internals of data systems making it possible to understand core trends in system design and to be one of the few who know how to design and evaluate systems. In addition, due to the way the course is taught (focus on interactive problem solving, open topics and the latest research results) this is also a great class for those who want to understand what CS research is all about and how to engage in doing research.
Efficient data analytics and system design is all about how we store and access the data. In this class, you are going to see how the same concepts appear again and again in numerous data-driven scenarios from NoSQL to neural networks.
If you took and liked CS165, you will like CS265 as well. From a material point of view CS265 moves on to consider additional topics as a continuation of CS165 such as distributed processing, transaction processing, graph processing, machine learning and more. In terms of the way the class is taught, it is even more interactive, and even more research oriented. Semester projects are actually on open research problems with the potential to lead to a publication and every class is focused on a single research paper, and understanding it in detail.
You may have heard stories about CS165 and wondering if CS265 is going to be equally hard or you may have taken CS165 and wondering if this is going to be a similar amount of work. CS165 and CS265 are different style of classes. While CS165 is much more focused on implementation leading to a full system prototype, CS265 is more focused on ideas and design. In other words, you may have written 5-10K lines of code (some even more!) for CS165 but in CS265 you are more likely going to write small amounts of code and mostly play with alternative ways to design a specific functionality, structure or algorithm to highlight the effect of different choices and to find out new ways to solve a specific problem.
IF you have taken CS165, CS161, CS261
GOTO next question;
ELSE
see below;
Background: Naturally, the more background you have the smoother your experience in 265 will be. Prior knowledge of C programming and systems programming, as well as a good understanding of computer architecture and in particular the memory hierarchy (cache memories) is very important for this class. Courses providing systems background (like CS50 and in particular CS61 or equivalent) are essential. Good hacking, algorithm designing, and data structures skills are also required.
If you are graduate student and have taken a mix of systems (database, operating and distributed systems) classes in the past, then you will be OK and we will provide enough background so you can follow. CS265 does satisfy the systems requirement towards a PhD.
If you are a senior in college and this is your last chance to take this class: if you have taken CS61 but no CS161 or CS165 then talk to the instructor to evaluate how fit your are for the class. If you have not taken CS61 but do have significant systems programming experience you may still qualify.
In all other cases, it is a better idea to take CS165 first.Just utilize all resources provided. Show up in class to participate in interactive sessions. There are also daily office hours and labs; show up as often as possible so we can help with anything you need! When you find yourself stuck with the project either with a design decision or just a bug, it is normal to struggle for a while — it is part of the learning process — but after some time grab your laptop and come by!
Especially if you have not taken CS165 it is a good idea to spend some time preparing before the semester starts and during the early weeks of the semester even if you consider yourself an expert systems student. The best approach is to browse some fundamental readings in data systems architectures. We propose that you take a look at the following texts from the CS165 readings:
Test 0: We provide a Test 0 that is designed to 1) help you get an idea about how fit you are for the class and 2) bootstrap your C coding skills. Essentially Test 0 consists of an independent data structure design and implementation in C that will allow you to practice basic system design, coding and debugging skills. In addition, several fundamental section videos are posted on the class website about system coding and profiling to help you with that.
You are responsible for understanding Harvard and Harvard Extension School policies on academic integrity and how to use sources responsibly. Not knowing the rules, misunderstanding the rules, running out of time, submitting "the wrong draft", or being overwhelmed with multiple demands are not acceptable excuses. There are no excuses for failure to uphold academic integrity. To support your learning about academic citation rules, please visit the Harvard College Guidelines to Avoid Plagiarism, where you'll find links to the Harvard Guide to Using Sources and two, free, online 15-minute tutorials to test your knowledge of academic citation policy. The tutorials are anonymous open-learning tools.
Harvard and the Extension School are committed to providing an accessible academic community. The Disability Services Office offers a variety of accommodations and services to students with documented disabilities. Please visit http://www.extension.harvard.edu/resources-policies/resources/disability-services-accessibility for more information and do not hesitate to contact prof. Idreos directly, by email, with any questions or concerns you might have.
Sections are offered only online as pre-recorded videos. We will be adding section videos through the semester based on the needs of the students. If you have questions for any one of the sections come by one of our daily OH and Labs.
These are a series of sections from CS165 which are useful for students who do not have prior experience or need to refresh their knowledge in C, and development tools needed for C programming.
In this section we will cover the basic knowledge of C required for this project. We will discuss the main features of the language and will focus on pointer arithmetics a key challenge when programming in C.
Section RecordingThis section introduces Test 0 (warm-up exercise), a standalone programming exercise that has two goals. First, it will help the students to understand the coding effort and skills needed to carry on the full project, by implementing a hash table. Second, it will be an integral part that can be used as-is in the full project.
Section RecordingThe section of this week is dedicated to memory hierarchy. Understanding memory hierarchy and how cache memory works is crucial for understanding how to build an efficient cache-aware data system. Hence, here, we will start from the basics of memory hierarchy, covering how caching works, what is an L3 and L2 shared cache, and what is an L1 private cache. We will discuss the differences between instruction and data caches and we will discuss how programs incur cache misses and how this affects performance.
In this section we will discuss important development tools. We will talk about debugging tools including [c]gdb and valgrind, and the build tool Gnu make. We will do so by example. The example code is available in the git repository listed below.
Last year's notes on git, valgrind, gcc, and gdb Section Recording
Section Git repository
Automatic
variables in Make
Secondary
expansion in Makefiles
Last year's
notes on git, valgrind, gcc, and gdb
After having a clear understanding of memory hierarchy, in this section, we will discuss techniques that allow us to build cache-conscious algorithms. We will discuss how to minimize cache misses and how to avoid branch mispredictions by removing branches altogether from our code.
In this section we will address performance optimizations and techniques to build high performance code in the context of the project. We will discuss performance monitoring tools (perf) which allow us to know exactly where does the execution time goes and help us understand whether our implementation is efficient, and where are any possible performance bottleneck.
These are a series of sections for you to kickoff your class projects.
In this section we will introduce the basic knowledge, i.e., how a neural network is trained and why we need activation checkpointing, for the ML Systems project. We also show you the starter codebase for your to kickoff your own experiments.
Section Recording Section SlidesIn this section we will introduce the NoSQL Systems project and the example experimental designs. We also show you the suggested toolchains that you can kickoff your own experiments.
Section Recording Section SlidesWhile the instructor will do a few lectures through the semester, the class is going to be primarily discussion based. Think of this as an extended brainstorming session, a round table discussion about a specific problem in each class. The goal is to create the maximum possible interaction.
Our discussion will aim at bringing up design trends and tradeoffs, as well as algorithmic issues. Another significant part of our discussions will focus on examining open problems and to highlight opportunities for innovation.
At the very beginning of the semester the instructor will do 4-5 lectures to provide the necessary background. After that, each class will be based on a student presentation about a recent research paper which will work as a trigger for the day’s brainstorming. Depending on the needs of the class, the instructor will do additional lectures during class time or during our extra research sessions.
Interaction does not stop at lecture time. CS265 is designed to maximize interaction as we truly believe this is the best way to learn; we offer daily office hours and labs.
Starting Week 1, Prof. Idreos will hold office hours during the week and additional OH will be offered periodically during the weekend. Labs are offered by the TFs. Rooms and slots: TBA. The goal of labs is to get hands-on help for the projects (coding). Bring your laptop and your questions about specific project parts you need help with. Labs are the place to go when you have a persistent bug, when you need help with a specific tool for the project (e.g., for debugging or performance testing) or to get feedback about the quality of your coding.
Based on the philosophy of the course, attendance in lectures, labs and office hours is optional. The best way to learn, though, is through discussion and interaction with the instructor and the TFs. Our classes are not about "lecturing" – they are about interaction. We hope to see you there!
All classes and interactive sessions in class will be recorded and will be available online. So even if you miss a class it will be easy to catch up and you can also use these recordings to recite specific material throughout the semester (e.g., to prepare for midterms).
Another component of the course is sections. Sections are used to deliver material about the class, i.e., to go more deeply into some of the concepts discussed in class, to do additional quizzes, or to deliver background material that is needed to follow next week’s class or for the project. There will be no actual section meeting. Instead, all sections will be recored by the teaching staff and videos will be posted online. The material posted will be tailored to present a step by step guide for any of the topics presented to make it easy to follow everything without having to be physically present in an actual section. However, if there are still questions about the material presented in sections, you will be able to ask those questions either during the daily office hours and labs.
Throughout the semester, on select days the instructor, and DASlab PhDs and postdocs, will discuss about research! First, DASlab researchers will present their recent work on data systems research and connect it with the material you are learning in class. Then, you will get the chance to talk with them about their research, open problems and be exposed to open research opportunities. Snacks and drinks will be provided.
When reading the papers we present in class focus on the following concepts/questions.
Each student will do at least one paper presentation during the semester. Presentations should follow similar guidelines as the Paper Reading Instructions. There should be 1-2 slides for each one of the nine core points in the paper reading instructions. In addition, there should be detailed slides that describe the core idea of the paper.
Your slides should not be a multiple sheets of bullet lists - in fact try to avoid bullet lists altogether - your slides should follow the generic formatting you will see in the first four lectures, that is: make slides as simple as possible - avoid text unless absolutely needed - no full phrases unless you need to give an exact definition of something - use figures and visual examples, one slide one message=each slide should have a single goal that you should be able to describe within a single phrase.
Your slides should be reviewed by the instructor at least 24 hours before the class you are presenting. The final deck of slides should be available 30 minutes before class so we can upload online. You are welcome to join for OH for help >> 1 while you prepare your slides!
The class is about state-of-the-art data system design. There is no textbook for that. Thus, we use recent research papers and surveys which will be posted on the course website, which you will have access to through the Harvard network.
We provide feedback continuously. The main thing that you will need feedback on is your semester project and the paper reviews. The way to get feedback is to show up to our daily office hours and labs and share your design decisions, code, and test results with the staff. In this way, you will get hands-on help and feedback.
Specifically for reviews we will hold a special session every second week to "review the reviews"
Every semester we arrange a few guest lectures by leaders in data system design from industry and academia. Past guest lecturers in our classes include: Guy Lohman from IBM Research, Erietta Liarou from EPFL Lausanne, Alkis Simitsis and Georgia Koutrika from HP Labs, Nikita Shamgunov from MemSQL, Laura Haas from IBM Research, Nga Tran from Vertica, Jignesh Patel from University of Wisconsin, Johannes Gherke, from Microsoft, Marcin Zukowski from Snowflake, Richard Hipp from SQLite, Ryan Johnson from Logicblox.
You will get the opportunity to both attend a guest lecture and to actively participate in discussions with our guest speakers.
We welcome feedback and ideas about the course at any point during the semester. Just come and chat with us during office hours! Tell us how you are keeping up and how we can make it easier for you.
CS265 is based on interaction. We want students actively participating in class and interactive sessions, asking and answering questions to maximize learning. In each class, we will bring a printed copy of the slides for each one of the students so you can follow along and to keep notes on paper. So you do not need your laptop or phones for notes or looking up the slides online. In fact, recent studies show that even if you only use a laptop for note taking, it can have a negative impact on how well you understand the material in class.
[The Pen Is Mightier Than the Keyboard: Advantages of Longhand Over Laptop Note Taking. Pam A. Mueller and Daniel M. Oppenheimer. Psychological Science. 2014, Vol. 25(6) 1159–1168]
There are cases where having a phone or laptop during class is necessary such as when you expect an important call or message or when you need the laptop to better follow the slides due to any issues with your eyes or ears. Just let the instructor know and all such cases will be granted permission to use any tools necessary.
We will use ED Discussions as a forum for online discussions. The links are posted on the class website. You are welcome to post any question that might help you understand the material better or help you with the project. Anonymous posting (to other students) will be enabled so that students feel more comfortable posting.
BASIC RULES: We only have a few basic rules so we can keep the forum functional and useful for the students as well as manageable for the staff.
This section supplements the basic syllabus with additional details that apply to extension school students.
CS265 is a heavily research oriented course that is structured in a very different way than other classes, valuing and promoting critical thinking. For most students this requires a transitions phase. Please check the syllabus and requirements carefully before committing to this course.
In addition, keep in mind that taking this course successfully will in practice require participation in OH and Lab sessions. Even if they are not mandatory, they are critical for students to understand how to think about the material and how to design solutions. Especially if you do not have all the background described in the syllabus (i.e., if you have not taken a research oriented systems course with a heavy systems project), you should budget time for frequent participation in both Labs and OH and many hours of additional work every week to build the foundations needed.
Lecture: Lectures will be broadcasted live. Lectures will also be available for on- demand broadcast within 24 hours after each class. Students will be able to watch the live or recorded broadcast through their browser. The link to the broadcasts for CS265 will be available through the canvas website for this class and will also be posted on the class website before the first lecture.
Participation: Extension school students will be able to participate live in classes, office hours and labs via web-conference tools (we will use Zoom). The course staff will be online with Zoom during each session that is marked as “remote” and you will be able to actively interact with the staff. Other than standard chatting and talking features Zoom also offers screen sharing features which can be used for when you need help with specific issues such as debugging.
Capturing Discussions: Given that a big portion of the class is based on interaction, extension school in cooperation with the class staff is always working to set-up a system with several microphones across the classroom so we can accurately and clearly capture brainstorming discussions and comments during class time. Microphones will “follow” the instructor.
Grading: Even though we encourage extension school students to utilize the opportunity to interact with the staff and participate in class live we know that for practical reasons this will not be possible for all remote students. For this reason for extension school students there will be no “class participation” grade. The rest of the course is exactly the same as what local students do.
For this reason the portion of the class participation grade (20%) will be distributed to other class components and the final grade break down is as follows: project (50%), presentation (20%) and reviews (20%). The 10% for the midway check-in completes the grade distribution for extension school.
Discussion Forum:Given that remote students have usually a different set of needs due to the distance, there is a separate forum tailored to extension school. Look at the class website for the forum link for extension school students.
Office Hours and Labs: Extension school OH and Labs take place remotely during the weekend, which is typically more convenient for most students. In this way, we can have more flexibility to accommodate students with day jobs that cannot attend during the week. The schedule will be posted at the beginning of the semester on the class website and the forum.
Starting Date: Note that usually extension school shows the class starting date to be one day after the actual starting date. In fact, this is when the first video will be available. However, extension school students will still be able to stream live the first class on the first day of classes and participate live as normal. Check the class website for the exact schedule if you want to participate live.
Graduate Credit: Extension school students who take the course for graduate credit should provide a detailed literature review of NoSQL key-value stores. This is due at the end of the semester along with the project and will account for 30% of the project grade. There will be a separate announcement early in the semester with guidelines on how to complete the literature review. You are most welcome to ask for feedback along the way from the staff.
 Prof. Stratos Idreos Instructor
(Room: SEAS 4.411)
Prof. Stratos Idreos Instructor
(Room: SEAS 4.411)
 Qitong WangHead TF
(Room: SEAS 4.435)
Qitong WangHead TF
(Room: SEAS 4.435)
 Utku SirinTeaching Fellow (Room: SEAS 4.435)
Utku SirinTeaching Fellow (Room: SEAS 4.435)
 Konstantinos KopsinisTeaching
Fellow
(Room: SEAS 4.435)
Konstantinos KopsinisTeaching
Fellow
(Room: SEAS 4.435)
 Milad Rezaei HajidehiTeaching Fellow (Room: SEAS 4.435)
Milad Rezaei HajidehiTeaching Fellow (Room: SEAS 4.435)
Each student completes one semester project. There are two kinds of semester projects: 1) a systems project (LLM Inference and ML System System), and 2) a research project.
The ML Systems Project for CS265 is designed to provide hands-on experience on the state-of-the-art systems for deep learning. It includes understanding the system architecture of modern deep learning frameworks, analyzing the compute memory trade-offs involved in training deep learning models and implementing an algorithm that navigates this trade-off. Systems projects will be done individually, each student is required to work on their own. This is a focused project that should not necessarily result in many lines of code (like the CS165 project), but will exercise your understanding of modern deep learning systems. The goal of this project is to implement an activation checkpointing algorithm in PyTorch. The project is structured into three stages: the first stage involves creating a profiler to gather performance metrics during the training process, the second stage involves implementing an algorithm that determines which activations to checkpoint based on the profiler's statistics, and the final stage requires modifying the execution strategy to implement the decisions made by the algorithm.
The LLM Inference Project for CS265 is designed to provide hands-on experience building a modern, high-performance inference stack. It focuses on understanding the end-to-end inference pipeline, identifying where latency and memory bandwidth are spent, and implementing core GPU operators to improve throughput. This is an individual systems project that emphasizes correctness first, then optimization, and may involve substantial debugging and performance tuning. The goal is to implement a lightweight LLM inference engine with C++ orchestration and CUDA kernels for key components (e.g., embedding, normalization, attention, and matrix multiplication), and then apply targeted optimizations such as better memory access patterns, tiling, and kernel fusion to reduce latency.
The research project, on the other hand, is much more tailored on design and proof of concept implementations trying to solve open problems. Research projects are tailored to give a taste of research to students and lead to publications. When working on a research project, students will work closely with the instructor and members of DASlab on active research projects of the lab. Students will work on groups of three. Such projects are mainly about thinking, reading and writing and much less about coding although proof of concept implementations will be our end target in some cases.
This year we will be working on the following research projects:
Research projects will be offered to students who have taken CS165 in the past and students who already have significant systems background. This will be done in consultation with the instructor.
In early February we will hold a special class to introduce both the systems project and the research projects in detail and this will be followed by a series of OH for clarifications. In the meantime students may browse the daslab website and learn more about the projects going on: http://daslab.seas.harvard.edu/, and the class website for examples of projects from past years.
In special cases where a student wants to work on an alternative research project, i.e., a project which is inspired by existing research that the student is already doing (e.g., as part of a PhD for a grad student or a continuation of the CS165 project for an undergrad) we will work to accommodate such requests on a case by case basis. This will be done in consultation with the instructor and only if students probably would not benefit from doing a systems project as they know this material already. Assuming there is a strong plan and drive for a specific project, such requests will most likely be granted.
For systems projects we will give out specific functionality and performance metrics you have to achieve as part of the description of the project. For research projects we will give out specific questions you need to answer when we set-up each individual research project.
There is no final or midterms. At the end of the semester each student will have a meeting with the instructor and another meeting with the TFs where students will demonstrate their projects and answer design questions about the project. [Tip: Past experience shows that frequent participation in office hours, brainstorming sessions and sections means that the instructor and the TFs are very well aware of your system and your progress which makes the final evaluation a mere formality for these cases.]
The systems project is an individual project: the final deliverable should be personal, you must write from scratch all the code of your system and all documentation and reports. Discussing the design and implementation problems with other students is allowed and encouraged! We will do so in the class and during office hours and brainstorming sessions. Research projects are going to be in groups of three and similar to the systems project we encourage discussions across teams but in the end each team should deliver a project that is clearly theirs.
All projects are due at the end of the semester and this is when they will be graded. The more input you give us, through the semester though, the more we can help you learn. In the systems project description you can find a detailed time- schedule that we propose you follow. Similarly, we will set up specific timelines for each research project. All timelines represent an ideal plan and you have the freedom to adjust according to your schedule.
There are no late days for reviews. This is because reviews are essential for you to follow each class.
Note: Experience says that every year a number of students cannot handle the freedom to self-pace, and end up significantly deviating from the schedule. We will send you frequent reminders but you should know that deviating from the schedule by more than a couple of weeks will most likely mean that you will not be able to finish the whole project by the end of the semester (unless you are an experienced systems student).
The goal here is to demonstrate that you are having decent progress and mainly to avoid falling behind. By early March each student working on a systems project should deliver 1) a design document, 2) a 45-minute presentation that describes the intended design for the whole project and, 3) at least two performance experiments that demonstrate early results (10%). A template of the expected design document will be provided early in the semester.
Below you can find some highlighted research projects from previous years that can serve as inspiration of what to expect from the research project.
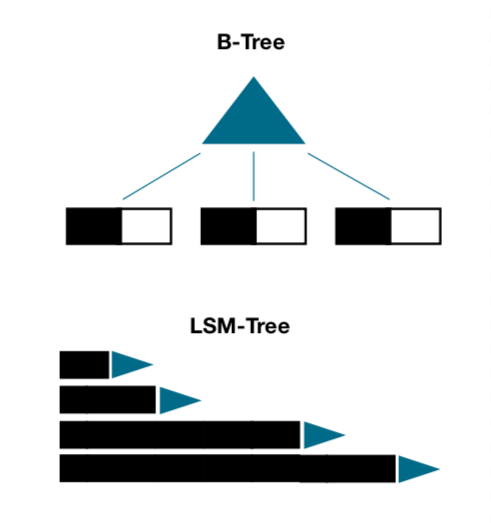
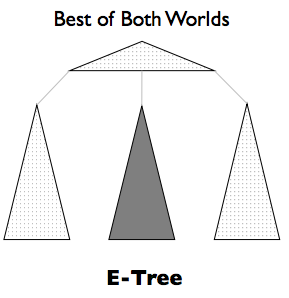
Many of our students in the past have successfully engaged in research projects with DASlab and published research papers. So far 11 undergraduate DASlab teams have made it to the finals of the ACM SIGMOD Undergraduate Research Competition. In 2016 we won first place with the work on adaptive denormalization, in 2017 we won first place with the work on evolving trees, in 2018 we won first place with the work on Splaying LSM-Trees, in 2019 we won first place with the work on LSM-Trees and B-Trees: The Best of Both Worlds, in 2020 we won first place with the work on Accurate Latency Prediction for Key-Value Storage Engines, in 2021 we won third place with the work on Learning Algorithms for Automatic Data Structure Design, and in 2022 we won first place with the work on Workload-Adaptive Filtering in Storage Engines.
Talk to the instructor at any point if you are excited about pursuing independent research during or after the course.