Adaptive Data Series Index
ADS+ builds a minimal tree during the indexing phase. The tree contains only iSAX representations, which are sufficient to build the index tree. The actual data series are only necessary during query time, i.e., in order to give a correct answer. In addition, not all data series are needed to answer a particular set of queries. In this way, ADS+ first creates all necessary iSAX representations and builds the index tree without inserting any data series.

When a query arrives (in the form of a data series), it is first converted to an iSAX representation.
The index tree is traversed searching for a leaf with an iSAX representation similar to that of the query.
Then, this leaf it is split until it becomes small enough.
In the case that the leaf node where the search finally ends contains only iSAX representations but not any data series, then all missing data series are fetched from the raw file.
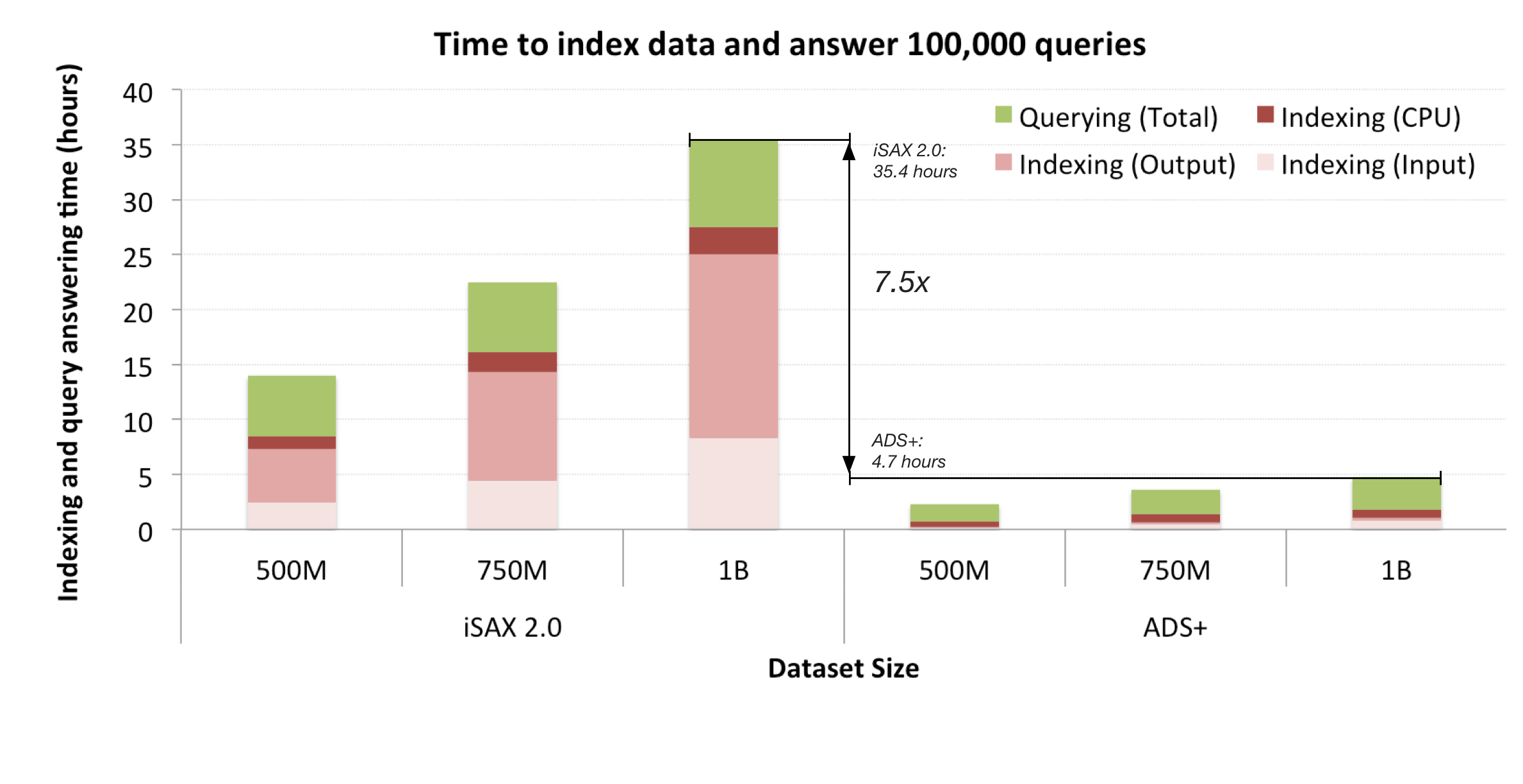
ADS+ achieves both faster indexing times and faster query answering times compared to the state-of-the-art iSAX 2.0 index.
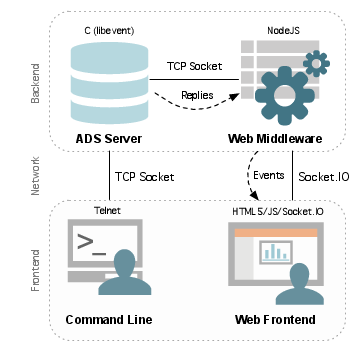
 ADS/ADS+
ADS/ADS+ RINSE
RINSE