Key-Value Stores: A Complex Design Space
Modern, persistent key-value stores are used throughout numerous applications, from social networks to document stores. We show that the design space of modern key-value stores is complex and that existing designs are sub-optimal.
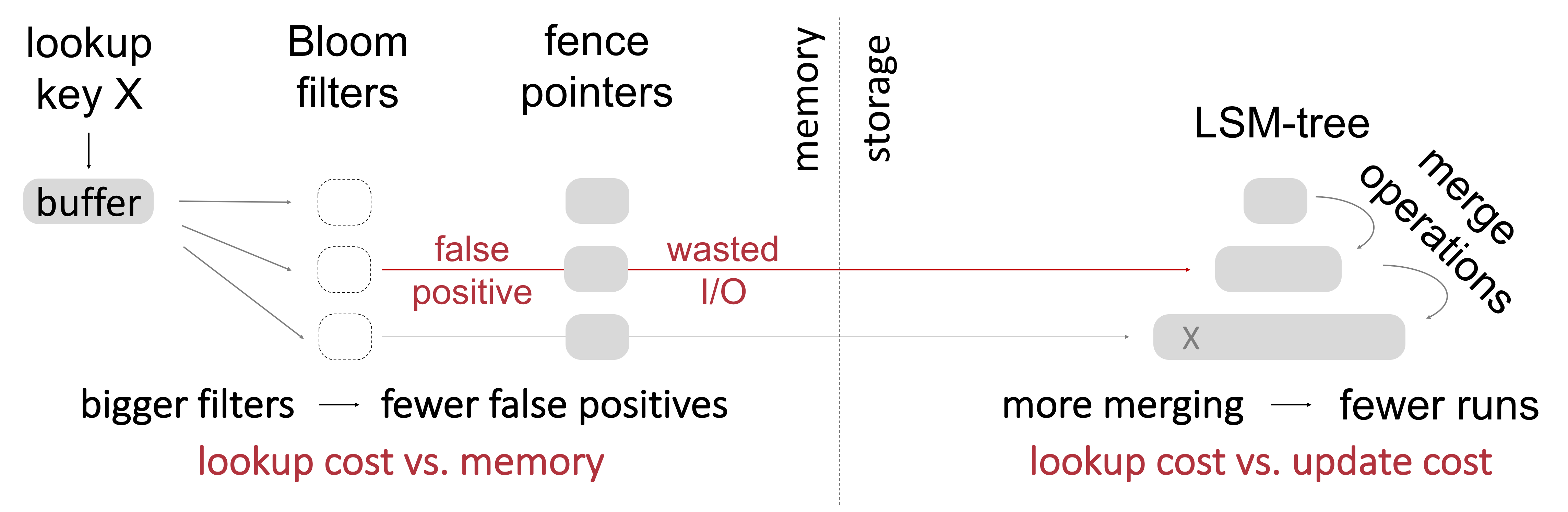
LSM-tree Background
Typically, key-value stores use an LSM-tree as a storage backend. LSM-trees balance lookup and update performance, by (i) buffering updates, (ii) creating sorted runs, and (iii) periodically merge them forming a series of sorted runs with exponentially increasing size. Searching for a value requires to probe in the worst case all sorted runs, a cost that can modern key-value stores mitigate by employing (a) fence pointers and (b) Bloom filters, both maintained in main-memory. The above design elements of key-value stores exhibit an intrinsic trade-off between lookup cost, update cost, and main memory utilization. Existing designs enable a suboptimal and difficult to tune trade-off among these metrics.