
Column Sketches are a new secondary indexing technique that work over column, row, and mixed data layouts and are aimed at providing consistent and efficient performance for predicate evaluation. Each Column Sketch has two components: 1) a compression map, and 2) a sketched column. You can see an example of the two on the right, with the compression map in the middle of the image and the sketched column on the right.
The compression map is a lossy function from values in the base domain to numerical codes, with the function being specifically designed to help predicate evaluation. The compression map is applied on a value-by-value basis to the base attribute(s) being sketched, creating the sketched column of smaller fixed width codes. Then, when queries arrive, they are first evaluated affirmatively or negatively for the vast majority of values using the lossily compressed sketched column. If needed, predicate evaluation then also checks the base data for some small amount of remaining values.

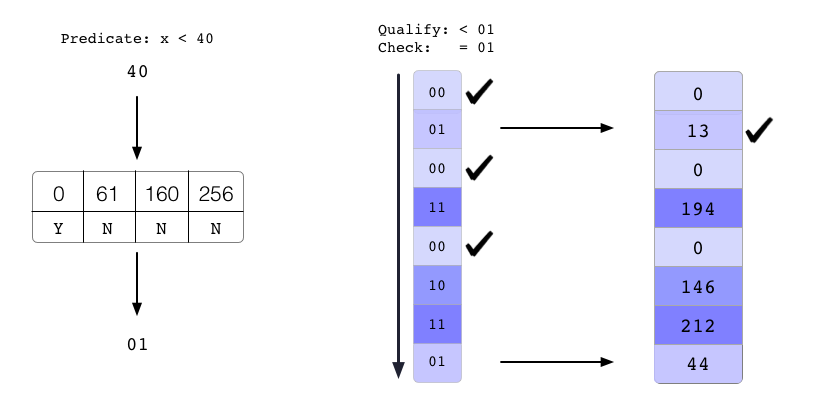
The creation of the compression map is what guarantees Column Sketch performance. The compression map does two things. First, it identifies the heavy hitters of the input domain. For each heavy hitter, it assigns it a unique code, i.e. the heavy hitter is the only value of the base domain which maps to that code. Second, the compression map makes the distribution of the codes approximately uniform, such that each code appears in the sketched column a nearly equal number of times. Due to these properties, a Column Sketch will never need to access many base data elements and will be able to guarantee that almost all values will be evaluated using the sketched column. An example of predicate evaluation using a Column Sketch is shown below.
In the example, the Column Sketch needs to access the base data twice for 8 tuples. But this is due to the small number of bits per value in the sketched column. In particular, if a Column Sketch has b bits for each code, then the base data will be accessed on average 1 out of every 2bvalues. Thus, for larger values of b, the Column Sketch will skip much more data. The result is that the Column Sketch ends up reading less data than a scan over the base data and thus gives performance benefits.


