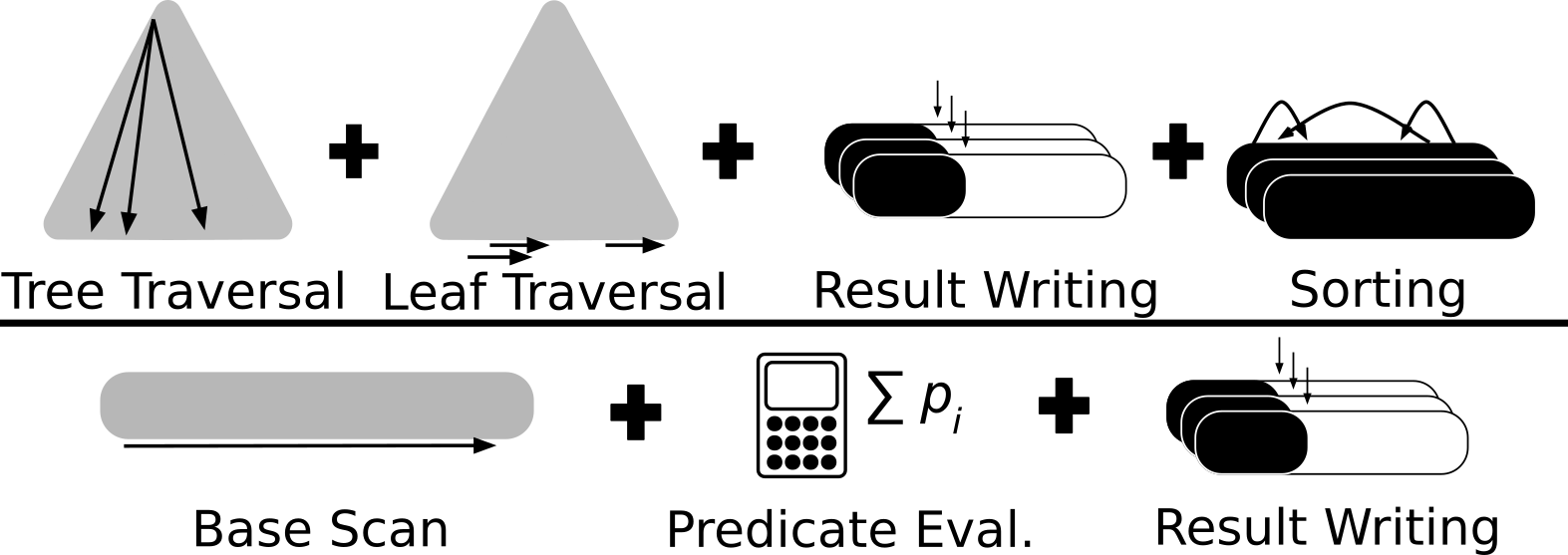
Modeling Access Paths
Access Path Selection happens based on the ratio between the expected cost of using concurrent index accesses and the expected cost of using a shared scan for a batch of queries. This ratio is comprised of seven key components, shown in the figure below. First, the index cost depends on (i) traversing the tree, (ii) traversing the leaves, (iii) writing the result, (iv) sorting the result (with the rowID order). The last step is needed to ensure a drop-in replacement for the sequential scan operator (and as a result, clustered accesses in other columns). Second, the scan cost, depends on (i) running a base scan of the data, (ii) evaluating the predicate, and (iii) writing the result.